
2·
8 days agoYeah, getting too close turns into an uncanny valley of sorts, where people expect all the edge cases to work the same. Making it familiar, while staying within its own design language and paradigms, strikes the right balance.
Yeah, getting too close turns into an uncanny valley of sorts, where people expect all the edge cases to work the same. Making it familiar, while staying within its own design language and paradigms, strikes the right balance.

Even the human eye basically follows the same principle. We have 3 types of cones, each sensitive to different portions of wavelength, and our visual cortex combines each cone cell’s single-dimensional inputs representing the intensity of light hitting that cell in its sensitivity range, from both eyes, plus the information from the color-blind rods, into a seamless single image.
This write-up is really, really good. I think about these concepts whenever people discuss astrophotography or other computation-heavy photography as being fake software generated images, when the reality of translating the sensor data with a graphical representation for the human eye (and all the quirks of human vision, especially around brightness and color) needs conscious decisions on how those charges or voltages on a sensor should be translated into a pixel on digital file.
my general computing as a subscription to a server.
You say this, but I think most of us have offloaded formerly local computing to a server of some kind:
All these things used to be local uses of computing, and can now be accessed from low powered smartphones. Things like Chromebooks give a user access to between 50-100% of what they’d be doing on a full fledged high powered desktop, depending on the individual needs and use cases.
Do MSI and ASUS have enough corporate/enterprise sales to offset the loss of consumer demand? With the RAM companies the consumer crunch is caused by AI companies bidding up the price of raw memory silicon well beyond what makes financial sense to package and solder onto DIMMs (or even directly solder the packages onto boards for ultra thin laptops).
I think with cheaper consumer desktops using IDE hard drives, that worked out of the box, but some more exotic storage configurations (SCSI, anything to do with RAID) were a little bit harder to get going.
My first Linux distro was Ubuntu in 2006, with a graphical installer from the boot CD. It was revolutionary in my eyes, because WinXP was still installed using a curses-like text interface at the time. As I remember, installing Ubuntu was significantly easier than installing WinXP (and then wireless Internet support was basically shit in either OS at the time).
Cutting edge chip making is several different processes all stacked together. The nations that are roughly aligned with the western capitalist order have split up responsibilities across many, many different parts of this, among many different companies with global presence.
The fabrication itself needs to tie together several different processes controlled by different companies. TSMC in Taiwan is the current dominant fab company, but it’s not like there isn’t a wave of companies closely behind them (Intel in the US, Samsung in South Korea).
There’s the chip design itself. Nvidia, Intel, AMD, Apple, Qualcomm, Samsung, and a bunch of other ARM licensees are designing chips, sometimes with the help of ARM itself. Many of these leaders are still American companies developing the design in American offices. ARM is British. Samsung is South Korean.
Then there’s the actual equipment used in the fabs. The Dutch company ASML is the most famous, as they have a huge lead on the competition in manufacturing photolithography machines (although old Japanese competitors like Nikon and Canon want to get back in the game). But there are a lot of other companies specializing in specific equipment found in those labs. The Japanese company Tokyo Electron and the American companies Applied Materials and Lam Research, are in almost every fab in the West.
Once the silicon is fabricated, the actual packaging of that silicon into the little black packages to be soldered onto boards is a bunch of other steps with different companies specializing in different processes relevant to that.
Plus advanced logic chips aren’t the only type of chips out there. There are analog or signal processing chips, or power chips, or other useful sensor chips for embedded applications, where companies like Texas Instruments dominate on less cutting edge nodes, and memory/storage chips, where the market is dominated by 3 companies, South Korean Samsung and SK Hynix, and American company Micron.
TSMC is only one of several, standing on a tightly integrated ecosystem that it depends on. It also isn’t limited to only being located in Taiwan, as they own fabs that are starting production in the US, Japan, and Germany.
China is working at trying to replace literally every part of the chain in domestic manufacturing. Some parts are easier than others to replace, but trying to insource the whole thing is going to be expensive, inefficient, and risky. Time will tell whether those costs and risks are worth it, but there’s by no means a guarantee that they can succeed.
No, X-rays are too energetic.
Photolithography is basically shining some kind of electromagnetic radiation through a stencil so that specific lines are etched into the top “photoresist” layer of a silicon wafer. The radiation causes a chemical change wherever a photon hits, so that stencil blocks the photons in a particular pattern.
Photons are subject to interference from other photons (and even itself) based on wavelength, so smaller wavelengths (which are higher energy) can fit into smaller and finer feature size, which ultimately means smaller transistors where more can fit in any given area of silicon.
But once the energy gets too high, as with X-ray photons, there’s a secondary effect that ruins things. The photons have too much leftover energy even after hitting the photoresist to be etched, and it causes excited electrons to cause their own radiation where high energy photons start bouncing around underneath, and then the resulting boundaries between the photoresist that has been exposed to radiation and the stuff that hasn’t becomes blurry and fuzzy, which wrecks the fine detail.
So much of the 20 years leading up to commercialized EUV machines has been about finding the perfect wavelength optimized for feature size, between wavelengths small enough to make really fine details and energy levels low enough not to cause secondary reactions.
2 lanes in each direction with a middle lane? That’s a big chunk of Texas, especially when weighted for population.
How will it reduce demand for parking? Do you envision the car will drop someone off and then drive away until it finds a parking spot that’s farther than the person would want to walk?
Plenty of high demand areas use human valet parkers for this issue. The driver drops off their car at the curbside destination, and then valets take the vehicle and park it in a designated area that saves the car driver some walking.
Then, the valet parking area in dense areas has tighter parking where cars are allowed to block in others. As a result, the same amount of paved parking spot can accommodate more cars. That’s why in a lot of dense cities, garages with attendants you leave keys with are cheaper than self-park garages.
Automated parking can therefore achieve higher utilization of the actual paved parking areas, a little bit away from the actual high pedestrian areas, in the same way that human valet parking already does today in dense walkable neighborhoods.
and people wouldn’t be happy waiting 5-10 minutes for their car to navigate back to them.
As with the comparison to valets, it’s basically a solved problem where people already do put up with this by calling ahead and making sure the car is ready for them at the time they anticipate needing it.
Once again reinventing buses and trains
Yes! And trains are very efficient. Even when cargo is containerized, where a particular shipping container may go from truck to train to ship, each individual containerized unit will want to take advantage of the scale between major hubs while still having the flexibility to make it between a specific origin and destination between the spokes. The container essentially hitches a ride with a larger, more efficient high volume transport for part of its journey, and breaks off from the pack for the portions where shared routing no longer make sense.
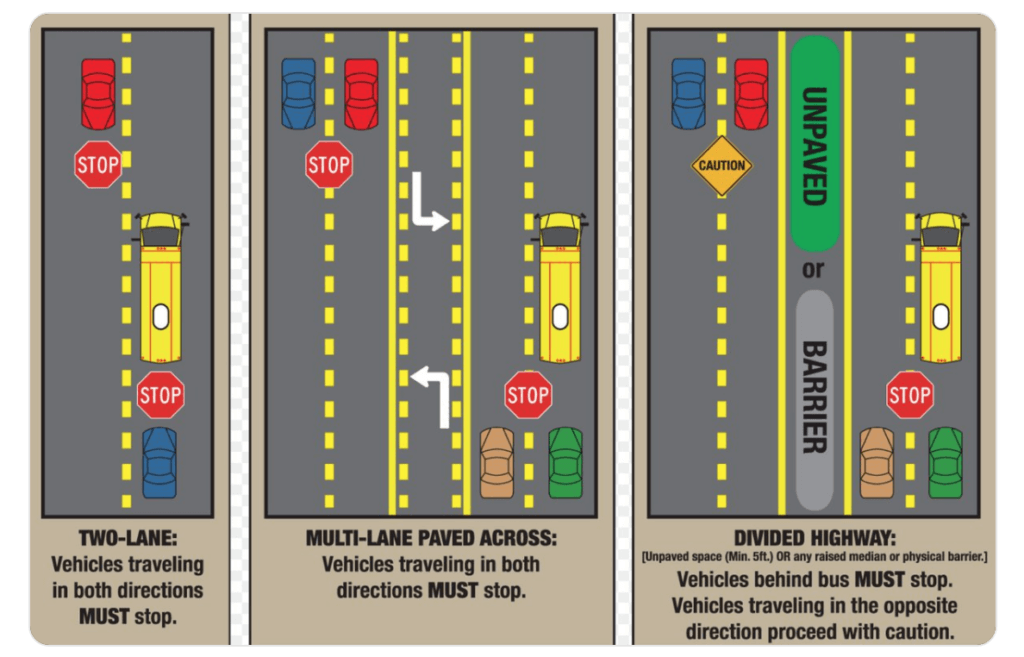
The default in most other states is that opposite direction traffic on a divided highway don’t have to stop. The states differ in what constitutes a divided highway, but generally at least 5 feet of space or a physical barrier between the lanes would qualify. In Texas, however, there is no exception for divided highways, and the key definition is “controlled-access highway,” which requires on/off ramps and physical barriers between traffic directions, or “different roadways,”
So for a 5-lane road where there are 2 lanes going in each direction with a center lane for left turns, Texas requires opposite direction traffic to stop, while most other states do not.
Waymos were violating a Texas state law that requires cars to stop when a school bus stops, even in 2+ lane roads separated by a paved median, even for traffic going in the opposite direction:
https://liggettlawgroup.com/wp-content/uploads/2019/09/School-bus-laws-img-1024x657.png
The requirements for opposite side traffic in multi-lane roads is pretty rare and might be unique to Texas. And yes, human drivers fuck this up all the time, too, leading to a lot of PSAs in Texas, especially for new residents.
It’s bizarre how if you drove through twenty bus stops in three days, you would not only lose your license but be in jail on multiple charges.
This is a relatively unique Texas law that requires cars to stop when school buses are loading or unloading passengers, including on the opposite side of the road going the other direction. The self driving companies didn’t program for that special use case, so it actually is a relatively easy fix in software.
And the human drivers who move to Texas often get tripped up by this law, because many aren’t aware of the requirement.
Paradoxically, the large scale deployment of self driving cars will improve the walkability of neighborhoods by reducing the demand for parking.
One can also envision building on self driving tech to electronically couple closely spaced cars so that more passengers can fit in a given area, such that throughout of passenger miles per hour can increase several times over. Cars could tailgate like virtual train cars following each other at highway speeds with very little separation, lanes could be narrowed to fit more cars side by side in traffic, etc.
Most importantly, the projections of fusion being 30 years away depended on assumptions about funding, when political considerations made it so that we basically never came anywhere close to those assumptions:
https://commons.wikimedia.org/wiki/File:U.S._historical_fusion_budget_vs._1976_ERDA_plan.png
Fusion was never vaporware. We had developed working weapons relying on nuclear fusion in the 1950’s. Obviously using a full blown fission reaction to “ignite” the fusion reaction was never going to be practical, but the core physical principles were always known, with the need for the engineering and materials science to catch up with alternative methods of igniting and harvesting the energy from those fusion reactions.
But we never really devoted the resources to figuring it out. Only more recently has there been significant renewed interest in funding the research to make it possible, and as you note, many different projects are hitting different milestones on the frontier of that research.
Writing 360 TB at 4 MB/s will take over 1000 days, almost 3 years. Retrieving 360 TB at a rate of 30 MB/s is about 138 days. That capacity to bitrate ratio that is going to be really hard to use in a practical way, and it’ll be critical to get that speed up. Their target of 500 MB/s is still more than 8 days to read or write the data from one storage platter.
I would argue, and I’m sure many historians and librarians and archivists would agree, that “general data backups” are essential human data. Storing the data allows for later analysis, which may provide important insights. Even things that seem trivial and unimportant today can provide very important insights later.
Honda won’t honor my 10-year powertrain warranty just because I yeeted my 2-year-old Civic off a bridge into salt water!

{kind=link}
{kind=link}
Apple supports its devices for a lot longer than most OEMs after release (minimum 5 years since being available for sale from Apple, which might be 2 years of sales), but the impact of dropped support is much more pronounced, as you note. Apple usually announces obsolescence 2 years after support ends, too, and stop selling parts and repair manuals, except a few batteries supported to the 10 year mark. On the software/OS side, that usually means OS upgrades for 5-7 years, then 2 more years of security updates, for a total of 7-9 years of keeping a device reasonably up to date.
So if you’re holding onto a 5-year-old laptop, Apple support tends to be much better than a 5-year-old laptop from a Windows OEM (especially with Windows 11 upgrade requirements failing to support some devices that were on sale at the time of Windows 11’s release).
But if you’ve got a 10-year-old Apple laptop, it’s harder to use normally than a 10-year-old Windows laptop.
Also, don’t use the Apple store for software on your laptop. Use a reasonable package manager like homebrew that doesn’t have the problems you describe. Or go find a mirror that hosts old MacOS packages and install it yourself.