

2·
25 days agoThe big problem is that we have long stepped over that line.
Now even when you pay you are still shown ads (maybe, but not surely, not-targeted) and your data is still scrapped and analyzed to hell and back.
I did nothing and I’m all out of ideas!
The big problem is that we have long stepped over that line.
Now even when you pay you are still shown ads (maybe, but not surely, not-targeted) and your data is still scrapped and analyzed to hell and back.
You can leak memory in perfectly safe Rust, because it is not a bug per se, an example is by using Box::leak
Preventing memory leaks was never in the intentions of Rust. What it tries to safeguard you from are Memory Safety bugs like the infamous and common double free.

I don’t have direct experience with RooCode and Cline, but I would be mighty surprised if they work with lesser models of even the old Qwen2-Coder 32B - and even that was mostly misses. I never tried the Qwen3 coder but I assume it is not drastically different.
Those small models are at most useful for some kind of smarter autocomplete, not to run a full tools framework.
BTW you could check out Aider too for a different approach, and they have a lot of benchmarks that can help you get an idea about what’s needed.
50501 (short for “50 protests, 50 states, 1 movement”) is an American progressivist grassroots political organization founded to protest the policies and actions of the second Donald Trump administration in the United States.
From wikipedia
The parade I assume is in reference to the birthday military parade for the 250th Army Anniversary of June 14, 2025. More here: wikipedia

You could try asking in [email protected] too, feddit.it is an italian speaking instance

I’m not sure if you are referring to this, but I’ve noticed some people overriding their comments after around 24h they have posted them - probably running an automated script. I assume they are doing it for perceived privacy reasons.
Thank you for commenting!
It was a pleasure! Thank you!
I’ve never used oobabooga but if you use llama.cpp directly you can specify the number of layers that you want to run on the GPU with the -ngl flag, followed by the number.
So, as an example, a command (on linux) from the directory you have the binary, to run its server would look something like:
./llama-server -m "/path/to/model.gguf" -ngl 10
Another important flag that could interest you is -c for the context size.
This will put 10 layers of the model on the GPU, the rest will be on RAM for the CPU.
I would be surprised if you can’t just connect to the llama.cpp server or just set text-generation-webui to do the same with some setting.
At worst you can consider using ollama, which is a llama.cpp wrapper.
But probably you would want to invest the time to understand how to use llama.cpp directly and put a UI in front of it, Sillytavern is a good one for many usecases, OpenWebUI can be another but - in my experience - it tends to have more half baked features and the development jumps around a lot.
As a more general answer, no, the safetensor format doesn’t directly support quantization, as far as I know


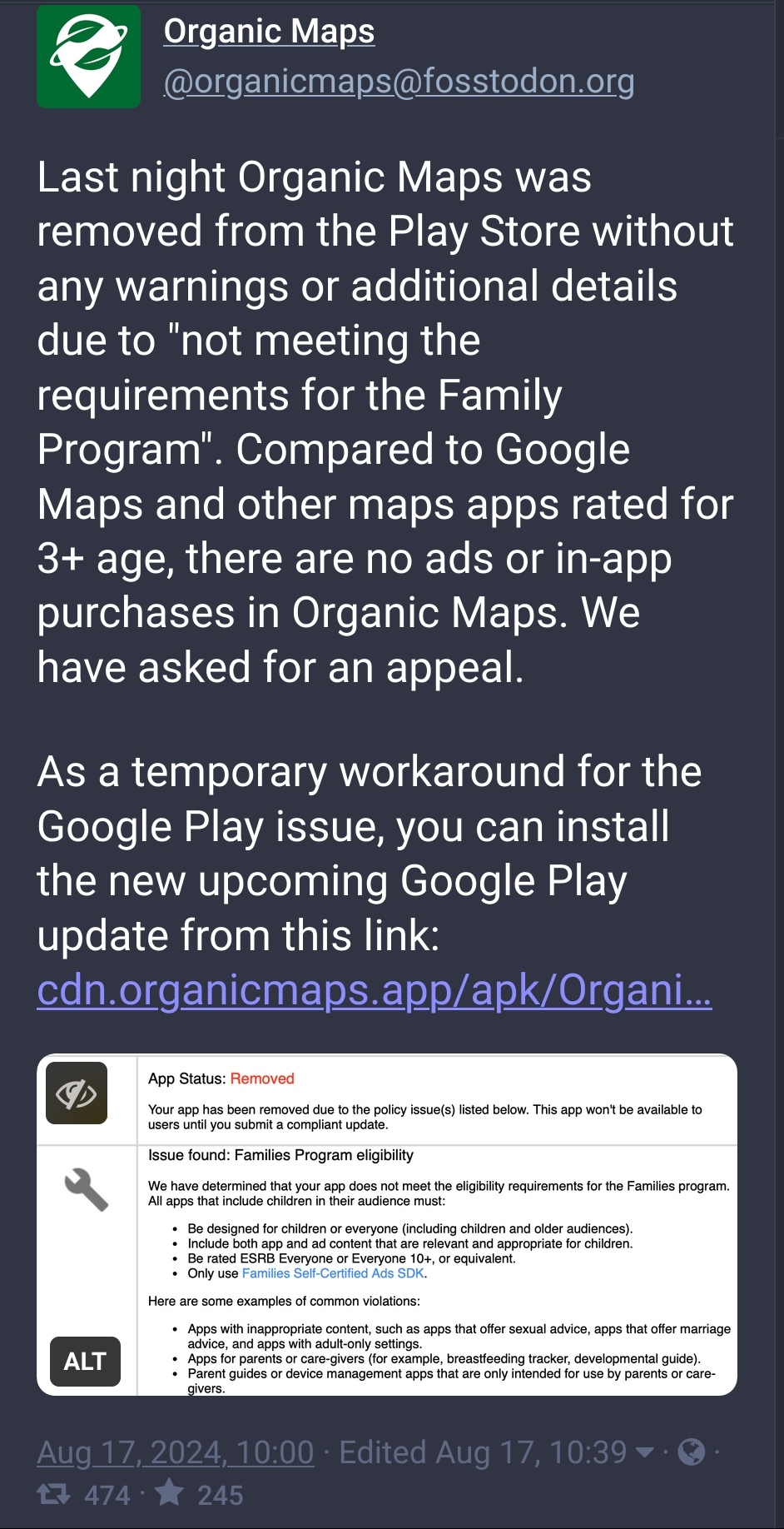{kind=link}
I’m not sure what you are really interested in, if you are searching frontier model’s capabilities with a good privacy policy… The answer is no.
If you are interested in privacy and can take an hit to performance, there’s lumo by proton, which I’ve never tried personally, but it should use open models, and there should be the list somewhere there.
Otherwise you can go European with Mistral’s Le Chat, which is not as good as the multibillion dollars companies offerings but it is quite good. I tend to use this one. Check the settings to disable data training.
Last but not least you can use a wrapper around the frontier models like the one offered by duckduckgo. There are many.
If you don’t mind paying there are no logs services that give you access to KimiK2 level models. Or you could spin up something on runpod or vast ai style gpu rentals.
So. It depends.