

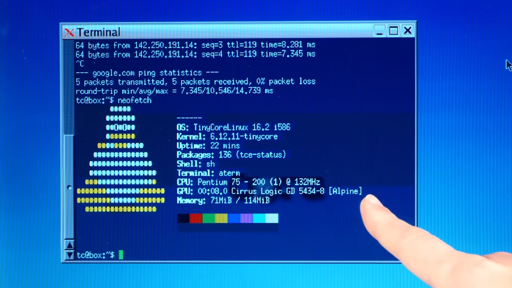
a pentium with 128mb of ram?? sure, if you were richie rich…
back in 1994 ram was around $100 per mb, so those specs are INSANE! i don’t even know if they made motherboards that could hanlde that much ram back then.
My 386 in 1993 had 4mb of ram, and i was jealous of all the kids with shinny new 486s with their 8mb of ram
8mb of ram didn’t become the standard until win98 demanded that much
Not surprising. Most Linux OSes are lightweight compared to Windows. And Moores’ Law slowed down in the last 10+ years.
128MB of RAM is a bit absurd for '94, though…
I can’t think of a reason why this should be surprising. Linux has been running on low-power embedded systems for quite a while.
Pentium 75 with… 128MB of ram lol. That’s LARGE!
My pentium 133 got upgraded to 128MB a few years after I had it. Definitely by 1999. It’s a 1995 proc so it’s not an unrealistic ram amount within the usable lifetime of the processor.
Sorta modern.
There’s been two big jumps in fundamental RAM usage during my time using Linux. The first was the move from libc to glibc. That tended to force at least 8MB as I recall. The second was adding Unicode support. That blew things up into the
gigabytehundreds of megabyte range.Edit: basing a lot of this on memory. Gigabyte range would be difficult for an OG Raspberry Pi, but I think it was closer to 128MB. That seems more reasonable with the difficulty of implementing every written language.
We can’t exactly throw out Unicode support, at least not outside of specific use cases. Hypothetically, you might be able to make architectural changes to Unicode that would take less RAM, but it would likely require renegotiating all the cross-cultural deals that went into Unicode the first time. Nobody wants to go through that again.
You can still compile a surprising number of modern programs and libraries without unicode support (that is, they provide an explicit compile flag to switch it off)—it’s just that no general-purpose distro does it by default. I’m not sure you can set up an entire unicodeless system using current software versions, but I wouldn’t bet against it, either. And glibc isn’t the only game in town—musl is viable and modern (it’s the default libc in Alpine Linux and an option for some other distros), and designed for resource-constrained environments. Those two things between them might bring down the size by considerable.
Wait, really? How does Unicode of all things increase RAM usage that much?
I assume because ASCII has a much smaller character set than unicode. ASCII fits in 7 bits, vs 21 bits for unicode.
I understand Unicode and its various encodings (UTF-8, UTF-16, UTF-32) fairly well. UTF-8 is backwards-compatible with ASCII and only takes up the extra bytes if you are using characters outside of the 0x00-0x7F range. E.g. this comment I’m writing is simultaneously valid UTF-8 and valid ASCII.
I’d like to see some good evidence for the claim that Unicode support increases memory usage so drastically. Especially given that most data in RAM is typically things other than encoded text (e.g. videos, photos, internal state of software).
It’s not so much character length from any specific encodings. It’s all the details that go into supporting it. Can’t assume text is read left to right. Can’t assume case insensitivity works the same way as your language. Can’t assume the shape of the glyph won’t be affected by the glyph next to it. Can’t assume the shape of a glyph won’t be affected by a glyph five down.
Pile up millions of these little assumptions you can no longer make in order to support every written language ever. It gets complicated.
Yeah, but that’s still not a lot of data, like LTR/RTL shouldn’t be varying within a given script so the values will be shared over an entire range of characters.
don’t know the details but my general IT knowledge says that: single unicode character/glyph can take up to 4 bytes instead of 1 (ascii).
Yes, but that shouldn’t generally explode the RAM usage by an order of magnitude. In terms of information amount, most of the data that computers handle is an internal binary representation of real-world phenomena (think: videos, pictures, audio, sensor data) and not encoded text.
No! One code point could be encoded by up to 4 UTF-8 code units, not glyph. Glyphs do not map to code points one to one. One glyph could be encoded by more than one code point (and each code point could be encoded by more than one code unit). Code points are Unicode thing, code units are Unicode encoding thing, glyphs are font+Unicode thing. For example the glyph á might be single code point or two code points. Single code point because this is common letter in some languages, and was used in computers before Unicode was invented, two code points because this might be the base letter a followed by an diacritic combining mark. Not all diacritic letters have single code point variant. Also emojis, they are single glyph but multiple code points, for example skin tone modifier for various faces emojis, or male+female characters combined into single glyph forming a family glyph. Also country flags are single glyph, but multiple code points. Unicode is BIG, there are A LOT of stuff in it. For example sorting based on users language, conversion to upper/lower case is also not trivial (google the turkish i).
It uses kernel version 6.12. That’s pretty damn modern.
But not the same standard C lib. That’s probably the most important thing outside of kernelspace.
That “Someone” turns out to just be Action Retro. Classic. But then again, maybe everyone isn’t already watching his wacky content regularly like I am.
He should give MenuetOS or KolibriOS a try instead of Tiny Core - could probably run with only 64MB of RAM instead of 128
Yeah it’s super weird the way this article was written, it feels AI almost but I can’t put my finger on it.
Let’s put tiny core Linux on literally anything I find at an ewaste recycler :-)
Or Haiku 🍂
He got Wi-Fi working on it as well too!
He’s on the fediverse too. @[email protected]
Aye! I was rummaging around his socials hoping he was on peertube as well, but alas.
Not yet. But I don’t think it would take much to get him doing it. He already runs his own mastodon instance and a number of other services himself.
My first Linux PC was a Pentium 75MHz with 32Mb RAM.
Mine was a 486DX50. I used that beast for quite some time. It ran great.
Probably around the same time I managed to find a used 386 for sale cheaply, and I bought it. I could play some of the early greats such as Dune 2, Day of the Tentacle, Monkey Island, while others were playing CD ROM games such as Red Alert.
But I didn’t care because I was still having fun, and lack of too many distractions allowed me to dive deeply into the fundamentals. When they moved on to the next cool game, I taught myself turbo Pascal and played with the serial ports and an old AT modem.
A few years later I got myself a 166MHz (MMX!) and got properly online (IRC, ICQ, etc) along with the rest and they had a hard time understanding how I was immediately so much better at understanding “their” stuff from the start than they ever would be.
Of course it is
Thats cool, but is there a way to replace that giant finger cursor
Its amazing how much less resources linux uses on my laptop compared to windows. I still use a lot of ram but that is from applications and I don’t have to worry about the os hogging so much. I can also reduce my gui effects if I want or such to get more resources but it uses so little I have not had to.
I’ve done that. It works well enough but my machine had 32mb of ram so I could only really use the tty
Ran Slackware on this exact same computer back in the day. Surprised there are any still functioning. Overclocking with jumpers on these boards was a revelation.










